基于分区技术的静态 R 树索引并行计算技术
(1. 中国科学院地理科学与资源研究所,北京 100101;2. 中国科学院研究生院,北京 100039;3. 中国水利水电科学研究院,北京 100044)
论文来源:计算机工程 第 35 卷 第 2 期
摘要:海量空间数据静态 R 树索引的加载时耗很大。该文利用关系数据库的优势,以空间数据分区存储技术为基础,提出针对自上而下的贪婪分裂算法的静态 R 树并行加载方法。该方法提高了海量数据批量加载效率,支持分区粒度的索引重建。论证与实验结果表明,并行构建的 R 树在合理空间…
关键词: 空间索引;静态 R 树;分区;并行计算
R 树索引性能优良,被广泛用于原型研究和商用空间数据库系统,它是目前最流行、最成功的多维索引结构之一[1]。但在海量空间数据的管理过程中,存在 R 树构建时耗过大、数据更新效率低、全局索引维护困难等问题。因此,本文针对静态 R 树加载过程良好的可并行性,采用并行计算技术并行化 R 树的构建过程,以提高索引构建效率。利用大型商用数据库分区技术管理海量空间数据,在逻辑上保证数据的无缝存储,确保查询效率并从物理层次上提高海量空间数据及其索引的可管理性、可用性和性能。
1 分区技术在空间数据库引擎中的应用
1.1 分区技术
数据库提供的分区功能可以提高许多应用程序的可管理性、性能和可用性。在 GIS 领域,将商用关系数据库作为空间数据的容器,采用分区技术提高空间数据访问的性能需要合理确定分区字段。在分区的基础上建立高效、易于管理维护的空间索引是成功应用分区技术的关键。
1.2 海量空间数据的高效存储
1.2.1 分区方案选择
常见的分区方法包括范围分区、Hash 分区、列表分区和组合分区。空间数据的特殊性在于其空间特性,根据 GIS 应用的特点,范围分区和列表分区较适合海量空间数据的大表分区存储。本文采用范围分区方法,通过预先设定图幅范围避免范围分区带来的各分区数据不均匀问题。
1.2.2 数据装载
为保证分区内空间对象地理范围的连续性,先根据数据的空间分布特征划分图幅范围,各图幅应该是整个数据范围的一个划分。如图 1 所示,根据数据的空间分布情况,将数据分为 4 个区,尽量保证各区数据量均衡。存储在数据库中4 个不同的表空间内,跨图幅的数据单独存放在分区 4 中。
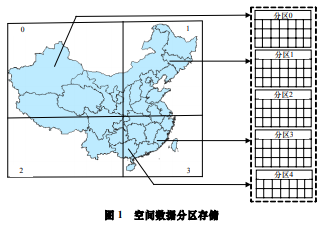
1.2.3 数据维护
基于分区技术的空间数据存储使空间数据能以分区为单位被维护并管理,如数据更新、索引维护等工作可以在单个分区内进行,而不影响其他分区中的数据,提高了海量数据的可管理性和可维护性。
2 静态 R 树的并行构建
2.1 存在的问题
空间数据的 R 树构建[2]是 CPU 密集型计算,且涉及大量I/O 操作,其时耗很大。已有很多方法可以加速 R 树的构建,如 Packed R 树、Hilbert Packed R 树、Bercken’s Buffer R 树、 Arge’s Buffered R 树等静态 R 树,但针对海量数据的 R 树构建时间仍然不能满足实际应用的要求。且全局空间索引维护困难,海量空间数据的 R 树索引会导致树深度增加,查询效率下降。存在小部分数据“脏区”时,必须对全局数据重建空间索引。
针对以上问题,在空间数据分区存储的基础上对分区数据并行计算空间索引,减少索引创建时间。在保证查询效率的同时,提高全局索引的可维护性。
2.2 基于 TGS 算法的 R 树并行构建
2.2.1 TGS 算法
Garcia 等人于 1998 提出自上而下的贪婪分裂(Top-down Greedy-Split, TGS)算法,其特点是自上而下地递归构建 R 树。
在 R 树的递归分裂过程中,通常采用扫描线分割空间中N 个对象的 MBR 面积作为 TGS 的自定义代价函数选择扫描线,即
f(r1, r2)=SArea(r1)+SArea(r2)
其中,SArea(ri)为被扫描线分割的第 i 个部分的面积。
每次递归过程中选择分割当前子集中 N 个对象的 MBR面积最小的扫描线,即
S=min(fi(r1, r2))
其中,i=1,2,…,n,n 为扫描线总数;S 为选取的扫描线;fi(r1, r2)表示第 i 条扫描线。
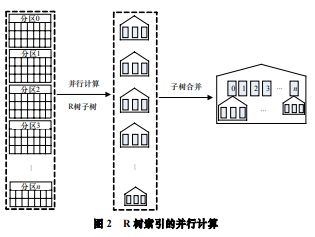
2.2.2 R 树的并行构建
如图 2 所示,并行计算 R 树索引的基本思想如下:采用并行 GIS 处理常用的典型策略[3],即 DCSO(Decomposition, Conquer, Stitch, Output)策略,本文数据分区存储实现了数据的自然分解,即问题分解;指定处理节点分别处理各分区数据,生成 R 树的子树;将各子树作为根节点的分支节点插入,完成整体索引创建,得到最终结果。
更多内容请查看pdf